Hola Gente,
este post es para recomendarles que le den un vistazo al sitio demo de Cummunity Charts Components versión 2 (CCC 2), es realmente muy bueno y a la ve una galería de lo que se puede hacer con estos componentes que son a cara visible de las CTools.
La página es: http://www.webdetails.pt/ccc2/
Naveguen por la página y prueben todas las opciones de cada gráfico.
Pueden descargar el instalador de CDF con CCC 2 habilitado desde aquí:
http://demo.webdetails.org:8080/pentaho/content/pentaho-cdf-dd/Render?solution=ClearWireless&path=&file=maindashboard.wcdf
Saludos
Mariano
jueves, diciembre 20, 2012
jueves, diciembre 13, 2012
Recursividad en MYSQL con Java
Hola Estimd@s,
he sacado algunas cosas del baúl y las quiero compartir, en este caso se trata de una clase Java que permite ejecutar consultas recursivas en MySQL, la idea surgió a partir de una necesidad en primera instancia y luego me base en la forma en que DB2 la lleva a cabo. Tengo la idea (cuando me haga de algún tiempo) de escribir algún articulo relacionado con recursividad en DB2 ya que es muy útil y por demás interesante. Por ahora solo esto.
Pueden descargar la clases desde aquí:
Copio el readme.txt que escribí para poder usar esta clase.
he sacado algunas cosas del baúl y las quiero compartir, en este caso se trata de una clase Java que permite ejecutar consultas recursivas en MySQL, la idea surgió a partir de una necesidad en primera instancia y luego me base en la forma en que DB2 la lleva a cabo. Tengo la idea (cuando me haga de algún tiempo) de escribir algún articulo relacionado con recursividad en DB2 ya que es muy útil y por demás interesante. Por ahora solo esto.
Pueden descargar la clases desde aquí:
Copio el readme.txt que escribí para poder usar esta clase.
Esta clase está basada en la idea de recursividad de DB2.
La clase ar.com.magm.jdbc.SQLRecursivo permite implementar recursividad en MySQL.
Aún no está bien testeada la indexación que es fundamental cuando se trabaja con muchos datos
La tabla con la que funciona la demo (clase Test) es:
CREATE TABLE `practico`.`arbol` (
`idPadre` integer NOT NULL,
`idHijo` integer NOT NULL,
`cantidad` integer NOT NULL,
PRIMARY KEY (`idPadre`, `idHijo`)
)
Agunos datos:
INSERT INTO `practico`.`arbol` VALUES
(3,8,1),
(5,6,3),
(2,5,2),
(1,4,2),
(1,3,2),
(1,2,1);
Forma el siguiente árbol:
1
+--2
| +--5
| +--6
|
+--3
| +--8
|
+--4
El uso es muy simple, solo hay que crear una instancia de la clase SQLRecursivo, el constructor pide
una conexión JDBC, ejemplo;
SQLRecursivo sqlRec = new SQLRecursivo(cn);
Luego llamar al método recursivo(consultaInicial, aliasTablaPadre, consultaRecursiva, indexKey)
Este método retornará el resultado en forma de ResultSet.
Los parámetros son:
@param consultaInicial
consulta que produce la población inicial de datos.
@param aliasTablaPadre
alias que se utilizará en la consulta recursiva para la tabla padre
@param consultaRecursiva
consulta que obtiene el resto de los datos en forma recursiva.
Esta consulta contiene la lógica de corte de cotrol.
Se hace referencia a la tabla padre con: //TablaPadre//
@param indexKey
representa la clave del índice/indices que se crearán sobre la
tabla padre, la forma es:
(opciones indice1)\t(clave indice1)\n(opciones indice2)\t(clave indice2),
en otras palabras el \n determina la cantidad de índices a crear,
el \t separa las opciones de la clave.
Para no crear ningún índice enviar "" o null.
Ejemplo:
UNIQUE CLUSTERED\tidHijo,idFiltroArbol,idFiltroGeneral\nNONCLUSTERED\tcc
Se crearán:
CREATE UNIQUE CLUSTERED INDEX IX0_##TablaPadre ON ##TablaPadre (idHijo,idFiltroArbol,idFiltroGeneral)
y
CREATE NONCLUSTERED INDEX IX1_TablaPadre ON ##TablaPadre (cc)
Se recomienda probar en el test las siguientes consultas:
String consultaInicial = "SELECT idPadre,idHijo FROM arbol where idPadre=1"; //Obtiene el árbol completo
para obtener el árbol completo o:
String consultaInicial = "SELECT idPadre,idHijo FROM arbol where idPadre=2"; //Obtiene el subarbol del nodo 2
En la consulta recursiva se puede (y en general se debe) hacer referencia a la tabla padre (consulta inicial),
esto se hace con la expresión: //TablaPadre//, esto se puede ver en el ejemplo. La tabla tiene un alias,
que este ejemplo es 'padre' y es el segundo argumento del método recursivo. Por ello en la consulta se ve:
... a.idPadre=padre.idHijo
String consultaRecursiva = "SELECT a.idPadre,a.idHijo FROM arbol a,//TablaPadre// WHERE a.idPadre=padre.idHijo";
Enjoy
Mariano
miércoles, diciembre 12, 2012
Valores de filas afectadas y claves identidad en DB2
Estimad@s,
expongo aquí algunas formas de trabajar con los datos recién insertados en tablas DB2.
Muchas veces es necesario conocer el último id insertado en una columna identity (auto-numérica) o también la última o últimas filas insertadas en una tabla.
Muchos desarrolladores tratan esto con algunas prácticas que no son muy buenas, algunos ejemplos pueden ser ejecutar una consulta del estilo SELECT MAX(id) FROM tabla luego de insertar, SELECT * FROM tabla WHERE descripcion='algún dato unique que se tenía antes de insertar' o almacenar últimos valores de clave en una tabla, esta última la peor de las prácticas.
Existen otros casos, pero casi todos tienen en común que no dan soporte a la concurrencia y que en general son muy ineficientes.
DB2 posee una serie de características que permiten lidiar con estos problemas y darles una solución sencilla y elegante, además se tendrá en cuenta la concurrencia y la eficiencia en la ejecución.
Secuencias:
Una manera puede ser utilizar secuencias. Las secuencias son objetos de la base de datos que permiten generar números en secuencia (valga aquí la redundancia) a pedido, además permite obtener el último número generado en la secuencia. Veamos un pequeño ejemplo de como crear y utilizar una secuencia.
Creamos la tabla que utilizaremos como ejemplo:
CREATE TABLE EJ_SECUENCIA (
id BIGINT NOT NULL,
descripcion VARCHAR(50) NOT NULL,
CONSTRAINT PK_EJEMPLO PRIMARY KEY (id)
);
Luego la secuencia seq1 que inicia en 1 e incrementa de 1.
CREATE SEQUENCE seq1 AS INTEGER START WITH 1 INCREMENT BY 1
La salida será:
1
-----------
1
1 registro(s) seleccionado(s).
Si ejecutamos ahora:
INSERT INTO EJ_SECUENCIA (id, descripcion) VALUES
(NEXTVAL FOR seq1, 'b'),
(NEXTVAL FOR seq1, 'c'),
(NEXTVAL FOR seq1, 'd');
Obtendremos:
SELECT * FROM DB2ADMIN.EJ_SECUENCIA
ID DESCRIPCION
-------------------- -------------
1 a
2 b
3 c
4 d
4 registro(s) seleccionado(s).
Como se puede apreciar el uso de las secuencia es muy sencillo y flexible.
Autoincrementales y filas afectadas:
Creamos la tabla de ejemplo:
CREATE TABLE EJ_IDS (
id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY,
descripcion VARCHAR(10) NOT NULL,
CONSTRAINT PK_IDS PRIMARY KEY (id)
);
Insertamos algunos valores:
SELECT * FROM EJ_IDS
Obtendremos:
ID DESCRIPCION
-------------------- ---------------
1 a
2 b
3 c
3 registro(s) seleccionado(s).
Luego ejecutando :
SELECT * FROM FINAL TABLE (INSERT INTO EJ_IDS (descripcion) VALUES ('e'),('f'),('g'))
La sentencia anterior cumplirá dos funciones, por un lado se insertarán tres nuevas filas y por otro se obtendrán de la consulta a la tabla 'FINAL TABLE'
ID DESCRIPCION
-------------------- -----------
4 e
5 f
6 g
3 registro(s) seleccionado(s).
También podemos utilizar 'FINAL TABLE' en modificaciones:
SELECT * FROM FINAL TABLE (UPDATE EJ_IDS SET descripcion = descripcion || '-nuevo' WHERE MOD(ID,2)=0)
Obtendremos:
ID DESCRIPCION
-------------------- -----------
2 b-nuevo
4 e-nuevo
6 g-nuevo
3 registro(s) seleccionado(s).
Además de 'FINAL TABLE' podemos utilizar 'NEW TABLE' la diferencia es que con 'NEW TABLE' obtendremos los valores de la tabla antes que se ejecuten las restricciones referenciales (claves foráneas) los triggers definidos como after:
Para obtener las filas borradas:
SELECT * FROM OLD TABLE (DELETE FROM EJ_IDS WHERE MOD(ID,3)=0)
ID DESCRIPCION
-------------------- -----------
3 c
6 c-nuevo
2 registro(s) seleccionado(s).
Espero que les sea útil.
Saludos
Mariano
expongo aquí algunas formas de trabajar con los datos recién insertados en tablas DB2.
Muchas veces es necesario conocer el último id insertado en una columna identity (auto-numérica) o también la última o últimas filas insertadas en una tabla.
Muchos desarrolladores tratan esto con algunas prácticas que no son muy buenas, algunos ejemplos pueden ser ejecutar una consulta del estilo SELECT MAX(id) FROM tabla luego de insertar, SELECT * FROM tabla WHERE descripcion='algún dato unique que se tenía antes de insertar' o almacenar últimos valores de clave en una tabla, esta última la peor de las prácticas.
Existen otros casos, pero casi todos tienen en común que no dan soporte a la concurrencia y que en general son muy ineficientes.
DB2 posee una serie de características que permiten lidiar con estos problemas y darles una solución sencilla y elegante, además se tendrá en cuenta la concurrencia y la eficiencia en la ejecución.
Secuencias:
Una manera puede ser utilizar secuencias. Las secuencias son objetos de la base de datos que permiten generar números en secuencia (valga aquí la redundancia) a pedido, además permite obtener el último número generado en la secuencia. Veamos un pequeño ejemplo de como crear y utilizar una secuencia.
Creamos la tabla que utilizaremos como ejemplo:
CREATE TABLE EJ_SECUENCIA (
id BIGINT NOT NULL,
descripcion VARCHAR(50) NOT NULL,
CONSTRAINT PK_EJEMPLO PRIMARY KEY (id)
);
Luego la secuencia seq1 que inicia en 1 e incrementa de 1.
CREATE SEQUENCE seq1 AS INTEGER START WITH 1 INCREMENT BY 1
La sintaxis de las secuencias en DB2 es muy amplia y permite definir muchas opciones como: ciclos, secuencias decrementales, etc.
Las secuencias tienen dos métodos asociados, PREVVAL que permite obtener el último número generado (no puede utilizarse luego de crear la secuencia, debe generarse al menos un valor antes de ejecutar este método) y NEXTVAL que permite generar un nuevo valor de la secuencia. Veamos con un ejemplo como insertar valores en la tabla EJ_SECUENCIA con esta secuencia.
INSERT INTO EJ_SECUENCIA (id, descripcion) VALUES (NEXTVAL FOR seq1, 'a');
VALUES (PREVVAL FOR seq1);
La salida será:
1
-----------
1
1 registro(s) seleccionado(s).
Si ejecutamos ahora:
INSERT INTO EJ_SECUENCIA (id, descripcion) VALUES
(NEXTVAL FOR seq1, 'b'),
(NEXTVAL FOR seq1, 'c'),
(NEXTVAL FOR seq1, 'd');
Obtendremos:
SELECT * FROM DB2ADMIN.EJ_SECUENCIA
ID DESCRIPCION
-------------------- -------------
1 a
2 b
3 c
4 d
4 registro(s) seleccionado(s).
Como se puede apreciar el uso de las secuencia es muy sencillo y flexible.
Autoincrementales y filas afectadas:
Creamos la tabla de ejemplo:
CREATE TABLE EJ_IDS (
id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY,
descripcion VARCHAR(10) NOT NULL,
CONSTRAINT PK_IDS PRIMARY KEY (id)
);
Insertamos algunos valores:
INSERT INTO EJ_IDS (descripcion) VALUES ('a'),('b'),('c');
Noten que solo es necesario dar valores a la columna descripcion, DB2 se encargará dar valores a la columna id.
Luego de consultar la tabla:
Obtendremos:
ID DESCRIPCION
-------------------- ---------------
1 a
2 b
3 c
3 registro(s) seleccionado(s).
Luego ejecutando :
VALUES (IDENTITY_VAL_LOCAL())
La salida será:
1
-----------
3
1 registro(s) seleccionado(s).
Para finalizar una herramienta excelente para obtener las filas afectadas, denominamos filas afectadas a las filas insertadas o que cumplen un predicado y por ello son modificadas o eliminadas.
SELECT * FROM FINAL TABLE (INSERT INTO EJ_IDS (descripcion) VALUES ('e'),('f'),('g'))
La sentencia anterior cumplirá dos funciones, por un lado se insertarán tres nuevas filas y por otro se obtendrán de la consulta a la tabla 'FINAL TABLE'
ID DESCRIPCION
-------------------- -----------
4 e
5 f
6 g
3 registro(s) seleccionado(s).
También podemos utilizar 'FINAL TABLE' en modificaciones:
SELECT * FROM FINAL TABLE (UPDATE EJ_IDS SET descripcion = descripcion || '-nuevo' WHERE MOD(ID,2)=0)
Obtendremos:
ID DESCRIPCION
-------------------- -----------
2 b-nuevo
4 e-nuevo
6 g-nuevo
3 registro(s) seleccionado(s).
Además de 'FINAL TABLE' podemos utilizar 'NEW TABLE' la diferencia es que con 'NEW TABLE' obtendremos los valores de la tabla antes que se ejecuten las restricciones referenciales (claves foráneas) los triggers definidos como after:
Para obtener las filas borradas:
SELECT * FROM OLD TABLE (DELETE FROM EJ_IDS WHERE MOD(ID,3)=0)
ID DESCRIPCION
-------------------- -----------
3 c
6 c-nuevo
2 registro(s) seleccionado(s).
Espero que les sea útil.
Saludos
Mariano
miércoles, diciembre 05, 2012
Expandir Colapsar con Pentaho Reporting salida HTML
Estimad@s,
esta vez escribo para compartir con ustedes algunos experimentos con Pentaho Reporting (PRD).
El caso es que viendo los ejemplos avanzados de PRD y tratando de mejorarlos en algunos casos, salen cosas como lo que les voy a contar en este post. Se trata de un método para expandir y colapsar cabeceras de grupo y detalles de forma muy sencilla.
Este ejemplo tiene como idea inicial, la propuesta por el ejemplo "HTML Actions.prpt", ejemplo que pueden encontrar si seleccionan del menú principal:
Help / Sample Reports / Advanced / HTML Actions
En el editor se ve así:

Ejecutándose en vista HTML así:

La verdad, muy bueno!, les recomiendo que lo vean.
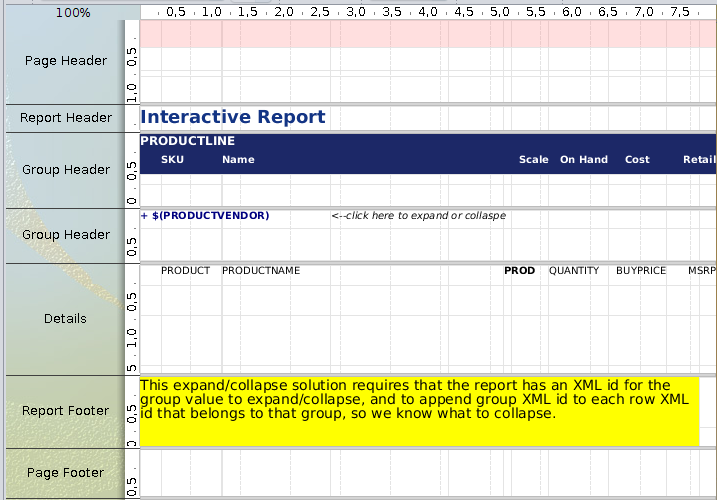
Es la posibilidad de ocultar partes de la jerarquía lo que me llamó la atención y en lo que me puse a experimentar. De los experimentos salió una pequeña serie de funciones javascript genéricas que permiten trabajar con hasta 9 niveles jerárquicos siguiendo dos simples pasos por cabecera de grupo. En este post explicaré en detalle como hacerlo. Ahora veamos el resultado final:

Los datos que contiene la tabla forman una jerarquía que puede verse en la imagen anterior y que reproduzco a continuación:
Zona
Año
( Cliente | Importe )
Una Zona tiene varios Años y en un Año por Zona pueden existir varios hechos, cada hecho es un importe de venta a un cliente determinado. La cardinalidad es uno a muchos de zona hacia año y de uno a muchos de zona/año hacia los hechos. Los datos están ordenados con el criterio de agrupamiento, esto es: Zona+Año, se puede agregar el cliente y/o el importe, aunque esto último es anecdótico.
La siguiente es una captura de la tabla:

Luego tenemos las librerías javascript requeridas, a estas librerías y/o reglas de estilo CSS, las agregamos en el header del documento principal, a esto lo hacemos editando el atributo append-header de Master Report. Lo anterior se traduce en algo tan sencillo como que se agregará ese snippet al header del documento HTML cuando el reporte se exporte a ese formato.
Respecto a JQuery, solo descarguen la versión mínima, la abren con un editor de textos, seleccionan todo, copian y lo pegan en esta sección (debe ser lo primero) rodeado de tags < script >
A continuación una captura de como acceder a esta característica en el reporte:

Impresionante las posibilidades que brinda PRD no?
No entraré en detalle de las funciones que he creado, si algun@ está interesad@, solo debe hacer el comentario pertinente. Sin duda que valoraré cualquier aporte o mejora al código.
Teniendo en claro esto, manos a la obra, ahora la parte más sencilla, desarrollar el reporte.








Bueno, hasta aquí nada nuevo bajo el sol, verdad?
Es una de las cosas que más me gusta de esto, la simpleza.
Lo que sigue es lo que le da dinamismo al reporte y permite u otorga la posibilidad de expandir/colapsar datos.
Implementación de la funcionanlidad de expandir/colapsar:
Solo tres atributos hay que configurar por grupo, dos de los cuales implementan la funcionalidad, el tercero es solo adorno visual.
El primer atributo que configuraremos será xml-id, este atributo se transforma luego en un atributo id para el elemento HTML que renderiza el elemento Message, particularmente se trata de un elemento td.
Veamos en una imagen como hacerlo y que valor colocar para el grupo año.

El valor del atributo xml-id para este caso es =CONCATENATE("j2_";[zona];"_";[año]), esta expresión data como resultado para la zona Este y el año 2012 "j2_Este_2012", esto generará un valor único para cada grupo, muy importante comprender el concepto.
La primera parte de la cadena "j2_" es parte de la implementación, 2 significa que el grupo está 2do en la jerarquía, en este caso el 1ero será el grupo zona.
El render HTML generará algo así:
< td id="j2_Este_2010" colspan="3" > - Año: 2012 < / td >
Si se comprendió lo anterior, se puede deducir el valor para el atributo xml-id de zona: =CONCATENATE("j1_";[zona])
Bien, si hasta aquí se comprendió, ya está, lo que resta es mecánico y muy simple.
Vamos a establecer el valor al atributo on-click de los elementos Message que representan los grupos.

En este caso, en la figura anterior, se muestra como establecer el valor para el grupo zona. El valor asignado es: ="expandCollapse(this, true)", esto es siempre igual, solo vale la pena aclarar que el segundo parámetro (valor true) implica que los valores de los grupos contienen como primer caracter un "+", esto será cambiado automáticamente por un "-" al expandir y vuelta al "+" al colapsar (and so on...).
Recuerden asignar el mismo valor al grupo año.
[Nota mental: estaría muy bueno poder enviar como parámetro el nombre de las clases CSS que deben ser asignadas al grupo cuando está colapsado y cuando está expandido. ¿Alguien se anima a aportar esta característica?]
El reporte ya posee la característica de expandir/colapsar en render HTML. Solo resta mejorar la apariencia en la interacción, hablo de que cuando el usuario pase el mouse por encima del grupo vea un cursor más acorde a lo que el grupo permite hacer. Lo haremos usando una clase CSS que ya está entre los snippets de los que hablamos al inicio. La clase se llama mouse y el código CSS es el siguiente:
.mouse {
cursor: pointer;
}
Bien, ahora solo debemos establecer la clase mouse a los elementos Message que representan los grupos del reporte. Veamos esto en una figura para el grupo año:

Repetir esto con el grupo zona y listo!
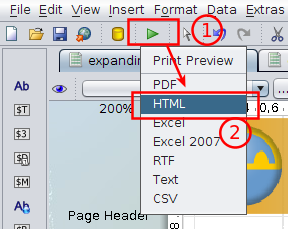
Para probarlo solo debemos seleccionar la vista previa en HTML:
esta vez escribo para compartir con ustedes algunos experimentos con Pentaho Reporting (PRD).
El caso es que viendo los ejemplos avanzados de PRD y tratando de mejorarlos en algunos casos, salen cosas como lo que les voy a contar en este post. Se trata de un método para expandir y colapsar cabeceras de grupo y detalles de forma muy sencilla.
Este ejemplo tiene como idea inicial, la propuesta por el ejemplo "HTML Actions.prpt", ejemplo que pueden encontrar si seleccionan del menú principal:
Help / Sample Reports / Advanced / HTML Actions
En el editor se ve así:
Ejecutándose en vista HTML así:

La verdad, muy bueno!, les recomiendo que lo vean.
Es la posibilidad de ocultar partes de la jerarquía lo que me llamó la atención y en lo que me puse a experimentar. De los experimentos salió una pequeña serie de funciones javascript genéricas que permiten trabajar con hasta 9 niveles jerárquicos siguiendo dos simples pasos por cabecera de grupo. En este post explicaré en detalle como hacerlo. Ahora veamos el resultado final:
Bien, aquellos que tengan un poco de curiosidad sigan adelante, el resto puede obviar de aquí en adelante.
Partimos de un reporte inicial que tiene muy poco, solo la fuente de datos (se trata de una tabla estática embebida en el reporte) y las librerías javascript necesarias ya embebidas, explicaré en que lugar y como hacerlo. Al reporte inicial lo pueden descargar desde aquí.
Para este caso he utilizado la versión experimental de PRD 4, la pueden descargar desde aquí, aunque se puede hacer sin problema con versiones anteriores (no se con exactitud a partir de cual).
Así se ve el reporte inicial en PRD:

Como pueden ver he ocultado todas las bandas que no son necesarias en el reporte.
Zona
Año
( Cliente | Importe )
Una Zona tiene varios Años y en un Año por Zona pueden existir varios hechos, cada hecho es un importe de venta a un cliente determinado. La cardinalidad es uno a muchos de zona hacia año y de uno a muchos de zona/año hacia los hechos. Los datos están ordenados con el criterio de agrupamiento, esto es: Zona+Año, se puede agregar el cliente y/o el importe, aunque esto último es anecdótico.
La siguiente es una captura de la tabla:

Luego tenemos las librerías javascript requeridas, a estas librerías y/o reglas de estilo CSS, las agregamos en el header del documento principal, a esto lo hacemos editando el atributo append-header de Master Report. Lo anterior se traduce en algo tan sencillo como que se agregará ese snippet al header del documento HTML cuando el reporte se exporte a ese formato.
Respecto a JQuery, solo descarguen la versión mínima, la abren con un editor de textos, seleccionan todo, copian y lo pegan en esta sección (debe ser lo primero) rodeado de tags < script >
A continuación una captura de como acceder a esta característica en el reporte:

Impresionante las posibilidades que brinda PRD no?
No entraré en detalle de las funciones que he creado, si algun@ está interesad@, solo debe hacer el comentario pertinente. Sin duda que valoraré cualquier aporte o mejora al código.
Teniendo en claro esto, manos a la obra, ahora la parte más sencilla, desarrollar el reporte.

Luego completar los datos del grupo.

Debemos definir ahora el grupo principal, para hacerlo debemos:

Luego completamos los datos:

Hasta aquí, la estructura del reporte debería quedar así:

Ahora coloquemos los elementos en el reporte.
El Detalle:
Primero un rectángulo, le damos el color (pueden usar el selector de combinación de color que está en la barra de herramientas) y las dimensiones. Luego arrastramos el campo cliente y el campo importe al detalle dentro del rectángulo. Será necesario darle una combinación de colores a los campos también. Pueden ver los detalles en la siguiente figura:

Los Grupos:
Como en el caso anterior, primero arrastramos un rectángulo en cada uno de las cabeceras de grupo. La cabecera de grupo que se encuentra en la parte superior pertenece al grupo de mayor jerarquía, en este caso se trata de zona. Luego de colocarlos en su lugar, habrá que asignar un color a cada rectángulo.

Procedemos ahora a colocar sobre los rectángulos los elementos que aportarán los datos, arrastraremos dos elementos Message, uno sobre cada rectángulo, le asignamos la combinación de color y establecemos el atributo value para cada uno.

Valores de value para:
zona: - Zona $(zona)
año: - Año $(año)
Bueno, hasta aquí nada nuevo bajo el sol, verdad?
Es una de las cosas que más me gusta de esto, la simpleza.
Lo que sigue es lo que le da dinamismo al reporte y permite u otorga la posibilidad de expandir/colapsar datos.
Implementación de la funcionanlidad de expandir/colapsar:
Solo tres atributos hay que configurar por grupo, dos de los cuales implementan la funcionalidad, el tercero es solo adorno visual.
El primer atributo que configuraremos será xml-id, este atributo se transforma luego en un atributo id para el elemento HTML que renderiza el elemento Message, particularmente se trata de un elemento td.
Veamos en una imagen como hacerlo y que valor colocar para el grupo año.

El valor del atributo xml-id para este caso es =CONCATENATE("j2_";[zona];"_";[año]), esta expresión data como resultado para la zona Este y el año 2012 "j2_Este_2012", esto generará un valor único para cada grupo, muy importante comprender el concepto.
La primera parte de la cadena "j2_" es parte de la implementación, 2 significa que el grupo está 2do en la jerarquía, en este caso el 1ero será el grupo zona.
El render HTML generará algo así:
< td id="j2_Este_2010" colspan="3" > - Año: 2012 < / td >
Si se comprendió lo anterior, se puede deducir el valor para el atributo xml-id de zona: =CONCATENATE("j1_";[zona])
Bien, si hasta aquí se comprendió, ya está, lo que resta es mecánico y muy simple.
Vamos a establecer el valor al atributo on-click de los elementos Message que representan los grupos.

En este caso, en la figura anterior, se muestra como establecer el valor para el grupo zona. El valor asignado es: ="expandCollapse(this, true)", esto es siempre igual, solo vale la pena aclarar que el segundo parámetro (valor true) implica que los valores de los grupos contienen como primer caracter un "+", esto será cambiado automáticamente por un "-" al expandir y vuelta al "+" al colapsar (and so on...).
Recuerden asignar el mismo valor al grupo año.
[Nota mental: estaría muy bueno poder enviar como parámetro el nombre de las clases CSS que deben ser asignadas al grupo cuando está colapsado y cuando está expandido. ¿Alguien se anima a aportar esta característica?]
El reporte ya posee la característica de expandir/colapsar en render HTML. Solo resta mejorar la apariencia en la interacción, hablo de que cuando el usuario pase el mouse por encima del grupo vea un cursor más acorde a lo que el grupo permite hacer. Lo haremos usando una clase CSS que ya está entre los snippets de los que hablamos al inicio. La clase se llama mouse y el código CSS es el siguiente:
.mouse {
cursor: pointer;
}
Bien, ahora solo debemos establecer la clase mouse a los elementos Message que representan los grupos del reporte. Veamos esto en una figura para el grupo año:

Repetir esto con el grupo zona y listo!
Para probarlo solo debemos seleccionar la vista previa en HTML:
Bien, hemos finalizado, espero que les sea de utilidad.
Pueden descargar la versión final desde aquí.
Saludos
Mariano
jueves, noviembre 29, 2012
Pentaho Bi-Server 48 y allegados
Hola Gente,
Hace un par de horas han publicado las nuevas versiones CE de Pentaho, se trata de la versión 4.8 del BI-Server y PME, la esperada versión 4.4 de PDI, la versión 3.9.1 de PRD, la versión 3.5 de Mondrian (esperamos la 4!) y sus herramientas (PSW y PAD).
La verdad, que solo lo ejecuté, pero al iniciarlo me encontré con la grata sorpresa que ya viene con Marketplace.
Archivos en: http://sourceforge.net/projects/pentaho/files/?source=navbar
Enjoy
Saludos
Mariano
Hace un par de horas han publicado las nuevas versiones CE de Pentaho, se trata de la versión 4.8 del BI-Server y PME, la esperada versión 4.4 de PDI, la versión 3.9.1 de PRD, la versión 3.5 de Mondrian (esperamos la 4!) y sus herramientas (PSW y PAD).
La verdad, que solo lo ejecuté, pero al iniciarlo me encontré con la grata sorpresa que ya viene con Marketplace.
Archivos en: http://sourceforge.net/projects/pentaho/files/?source=navbar
Enjoy
Saludos
Mariano
Generar un solo archivo HTML con la API de Pentaho Reporting
Estimad@s,
este post es muy puntual, en los últimos días estuve lidiando con la API de Pentaho Reporting a raíz del desarrollo de node-prd y node-prd-web-example, la verdad que para cubrir las funciones básicas no tuve inconvenientes, pero me surgieron problemas al querer trabajar con salidas HTML.
Por defecto la salida que genera la llamada al método HtmlReportUtil.createDirectoryHTML(MasterReport report, String path) se compone de un archivo html por cada página que el reporte genere, eso no sería problema si estuviesen conectados entre sí, pero no lo están, por ende para mostrarlos es un problema, he visitado varios foros y he consultado un libro sobre el tema, pero nada. Por otro lado si lo generaba utilizando la opción del editor, lo generaba en un solo archivo y se veían perfecto las imágenes.
La solución vino de la mano del hecho que este software es open source, sencillamente descargué el código fuente y en la clase: org.pentaho.reporting.designer.core.actions.report.preview.PreviewHtmlAction
Está el código que utiliza el editor, al final quedó algo así:
Saludos
Mariano
este post es muy puntual, en los últimos días estuve lidiando con la API de Pentaho Reporting a raíz del desarrollo de node-prd y node-prd-web-example, la verdad que para cubrir las funciones básicas no tuve inconvenientes, pero me surgieron problemas al querer trabajar con salidas HTML.
Por defecto la salida que genera la llamada al método HtmlReportUtil.createDirectoryHTML(MasterReport report, String path) se compone de un archivo html por cada página que el reporte genere, eso no sería problema si estuviesen conectados entre sí, pero no lo están, por ende para mostrarlos es un problema, he visitado varios foros y he consultado un libro sobre el tema, pero nada. Por otro lado si lo generaba utilizando la opción del editor, lo generaba en un solo archivo y se veían perfecto las imágenes.
La solución vino de la mano del hecho que este software es open source, sencillamente descargué el código fuente y en la clase: org.pentaho.reporting.designer.core.actions.report.preview.PreviewHtmlAction
Está el código que utiliza el editor, al final quedó algo así:
ResourceManager manager = new ResourceManager();
manager.registerDefaults();
Resource res = manager.createDirectly(
new URL("file:/home/mariano/reporte.prpt"),
MasterReport.class);
MasterReport report = (MasterReport) res.getResource();
//Carpeta contenedora del archivo html, los estilos e imágenes
File tempDir = new File("/home/mariano/htmlTemp");
if(!tempDir.exist())
tempDir.mkdirs();
//Nombre del archivo html. (recomiendo generarlo de forma aleatoria)
String fileName = "index.html";
//Se establece la carpeta en la cual se genera la salida HTML
final FileRepository targetRepository = new FileRepository(tempDir);
final ContentLocation targetRoot = targetRepository.getRoot();
//Se prepara el procesador del reporte, usando la implementación de HTML
final HtmlPrinter printer = new AllItemsHtmlPrinter(report.getResourceManager());
printer.setContentWriter(targetRoot, new DefaultNameGenerator(targetRoot, fileName));
printer.setDataWriter(targetRoot,
new DefaultNameGenerator(targetRoot, "content"));
printer.setUrlRewriter(new FileSystemURLRewriter());
final StreamHtmlOutputProcessor outputProcessor =
new StreamHtmlOutputProcessor(report.getConfiguration());
outputProcessor.setPrinter(printer);
final StreamReportProcessor reportProcessor =
new StreamReportProcessor(report, outputProcessor);
//Se genera la salida HTML
reportProcessor.processReport();
reportProcessor.close();
Que bueno disponer del código fuente!Saludos
Mariano
miércoles, noviembre 28, 2012
node-prd-web-example
Estimad@s,
Ya está disponible la versión 0.0.1-beta7 de node-prd, tiene varias mejoras, entre ellas la posibilidad de configurar una conexión JDBC ad-hoc y pasar la consulta SQL. También he creado una sitio web node Express, se puede descargar desde: https://github.com/magm3333/node-prd-web-example
El sitio demo muestra la potencia de node-prd, es muy simple de instalar y probar, además disponen de todo el código fuente si desean indagar.
Gracias a Darío Bernabeu (amigazo!) por el reporte.
Adjunto algunas screenshots:

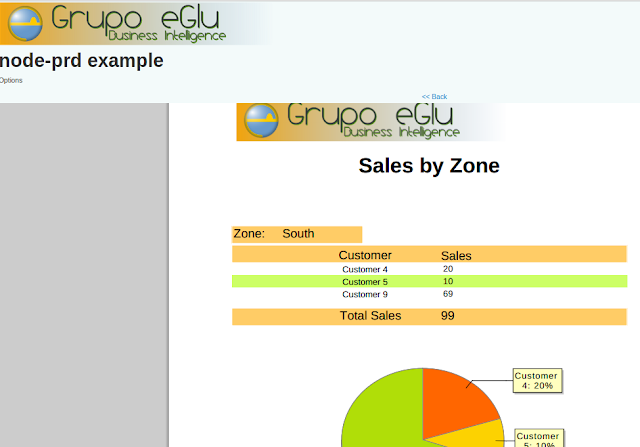
Aún quedan algunos detalles que pulir, pero ya está funcionando.
Espero ideas y reportes de bugs.
Saludos
Mariano
Ya está disponible la versión 0.0.1-beta7 de node-prd, tiene varias mejoras, entre ellas la posibilidad de configurar una conexión JDBC ad-hoc y pasar la consulta SQL. También he creado una sitio web node Express, se puede descargar desde: https://github.com/magm3333/node-prd-web-example
El sitio demo muestra la potencia de node-prd, es muy simple de instalar y probar, además disponen de todo el código fuente si desean indagar.
Gracias a Darío Bernabeu (amigazo!) por el reporte.
Adjunto algunas screenshots:


Aún quedan algunos detalles que pulir, pero ya está funcionando.
Espero ideas y reportes de bugs.
Saludos
Mariano
jueves, noviembre 22, 2012
Módulo node-prd
Hola Gente,
les comento que estoy desarrollando un módulo que he denominado "node-prd", es un módulo para node.js, que permite trabajar con informes confeccionados con Pentaho Report (PRD).
La versión actual es 0.0.1-beta8 y soporta parámetros y salidas pdf, xls, xlsx, rtf y html. En cuanto a fuentes de datos utiliza la definida en el informe (JDBC no JNDI) y una denominada NamedStatic que permite enviarle los datos en formato JSON desde la aplicación.
Pronto postearé más sobre node.js, ya que si bien hace poco tiempo que trabajo con esa tecnología, me parece increlíble y ya tengo mucho material e ideas sobre el tema.
Encontrarán todo lo necesario para probar este módulo aquí: https://github.com/magm3333/node-prd
Saludos
Mariano
les comento que estoy desarrollando un módulo que he denominado "node-prd", es un módulo para node.js, que permite trabajar con informes confeccionados con Pentaho Report (PRD).
La versión actual es 0.0.1-beta8 y soporta parámetros y salidas pdf, xls, xlsx, rtf y html. En cuanto a fuentes de datos utiliza la definida en el informe (JDBC no JNDI) y una denominada NamedStatic que permite enviarle los datos en formato JSON desde la aplicación.
Pronto postearé más sobre node.js, ya que si bien hace poco tiempo que trabajo con esa tecnología, me parece increlíble y ya tengo mucho material e ideas sobre el tema.
Encontrarán todo lo necesario para probar este módulo aquí: https://github.com/magm3333/node-prd
Saludos
Mariano
viernes, noviembre 16, 2012
Graphite - su arquitectura y componentes
Hola gente,
hoy les comentaré de forma sintética la arquitectura y componentes de Graphite.
Graphite está compuesto por:

hoy les comentaré de forma sintética la arquitectura y componentes de Graphite.
Graphite está compuesto por:
- Whisper: es una librería de base de datos round-robin, almacena exclusivamente time series, esto es un número o valor y una estampa de tiempo asociada a dicho valor. Si, así de simple. Whisper ejecuta operaciones básicas como: create, update y fetch. La operación create crea un nuevo archivo en formato Whisper, update escribe nuevos valores en el archivo, cada uno de estos valores se denomina data point = (valor, timestamp), por último, fetch se encarga de obtener los data points del archivo Whisper. Whisper es utilizado por Graphite, pero puede ser embebido en otras aplicaciones.
- Carbon ( o carbon-cache): es un demonio encargado de recibir las peticiones de almacenamiento de data points asociados a una métrica por parte de los clientes y persistirlos utilizando Whisper. Carbon está pensado para manejar grandes cantidades de peticiones con bajo overhead. Las métricas son cualquier valor que sea mensurable y que varíe en el tiempo, se representan con una cadena separada por puntos (.), por ejemplo: database.servers.mysql.queries.slow, Whisper almacenará los datos de esta métrica de la siguiente manera .../database/servers/mysql/queries/slow.wsp. Carbon no transmite información alguna a los clientes, solo recibe en forma de texto plano los datos de la métrica, por ejemplo: database.servers.mysql.queries.slow 1 1278346753, luego intentará escribirlos mediante Whisper lo más rápido posible.
- Web Front End: es una aplicación web sencilla, pero permite realizar la tarea de generar gráficos de forma muy rápida y sin tantas "vueltas". Esta interface web permite además crear dashboards y administrar eventos a los cuales luego nos podremos suscribir.
Adjunto una figura (fuente: http://www.aosabook.org/en/graphite.html) que ayuda a comprender mejor lo rescripto en los puntos anteriores.
Por hoy nada más, en breve seguimos con este tema.
Saludos
Mariano
jueves, noviembre 15, 2012
Graphite - Simple y potente
Estimad@s,
esta vez es para contarles acerca de una herramienta que me ha impresionado por su simplicidad y potencia, se trata de Graphite, una herramienta opensource escrita en Python con licencia Apache 2.0. Ya en su titulo "Scalable Realtime Graphing" nos invita al menos a hecharle una mirada, aunque con mi poca experiencia, creo que este titulo no termina de definir las cosas buenas de Graphite.
Que hace graphite? para que sirve?, bueno, en otro artículo nos cuentan en simples palabras que Graphite "almacena números que varían con el tiempo y luego permite graficarlos", esto es cierto, pero las características de Graphite son muchas más.
Una de las cosas que más me ha gustado es la simplicidad con la cual tratabajos con Graphite, ahora bien, hay muchas herramientas que nos faciitan este tipo de trabajo, entonces cual es el valor agregado de Graphite, bien, el valor agregado, desde mi punto de vista, es que nos prmitirá almacenar grandes cantidades de datos que serán obtenidos de forma muy eficiente y simple.
Graphite presta servicios para de inyección y obtención de datos, estos servicios no se limitan al uso de un protocolo, en realidad podemos consumir los servicios de diversas formas, entre ellas: http y sockets udp.
Los datos podrán ser obtenidos mediante consultas muy potentes y simples, además estos datos se pueden representar en diversos formatos: png, raw, csv, json y svg
Aquí adjuntaré una serie de características que no son de mi autoria, pertenecen aun colega y amigo cuyo blog es: http://menospeor.tumblr.com
------------------------------------------------------------------------------------------------------------------------------
1) Graphite introduce el concepto de "estadisticas como servicio (EAAS)". Su arquitectura perimte que tengas un servidor con graphite en algún lado y después consumas sus servicios desde distintos puntos. Esto es importante porque libera a las aplicaciones de toda la complejidad relacionada. Al momento de realizar una operación que queremos registrar, normalmente basta UNA SOLA LINEA DE CÓDIGO para enviar el dato y olvidarse del asunto.
2) La característica de realtime es importante también Graphite esta preparado para soportar mucha carga, y cuenta con optimizaciones para poder obtener siempre los datos mas frescos. Por ejemplo, carbon va recibiendo datos y escribe a whisper en bloques, pero cuando le haces una consulta, te abstrae la diferencia entre "datos en cola" y "datos en disco". Esto es notable y es la única herramienta con base de datos round-robin (que conozco!) que lo hace. [Aclaración: hablaremos de carbon, whisper y la arquitectura de Graphite en futuros posts]
3) Comparado con rrdtool (mini post aca), otra diferencia importante es que podes indicar el timestamp de los datos a entrar. Por defecto se asume la hora actual, pero podes cargar datos en el futuro y en el pasado de manera muy sencilla. Esto es fundamental para hacer migraciones y en rrdtool no es para nada trivial obtener la misma funcionalidad. Ademas, y gracias a esta característica te permite enviar datos en lotes para mejorar la performance en red. Podes quedarte juntando datos y mandarlos todos juntos en una sola petición cada 10 minutos, por ejemplo.
4) Soporta Plugins! <-- data-blogger-escaped-aparte.="aparte." data-blogger-escaped-esto="esto" data-blogger-escaped-merece="merece" data-blogger-escaped-post="post" data-blogger-escaped-se="se" data-blogger-escaped-span="span" data-blogger-escaped-un="un">
Gracias Ale!
-------------------------------------------------------------------------------------------------------------------------------
Intentaré mostrar con algunos ejemplos la potencia simpleza y de Graphite:
Ante un requerimiento HTTP/GET de este tipo:
http://graphiteserver/render?target=stats.gauges.metricas.servers.server1.load&from=-10days
Donde stats.gauges.metricas.servers.server1.load es el nombre del indicador y el filtro de consulta es -10days. En otras palabras estoy requiriendo los datos acerca de la carga de mi server1 en los últimos 10 días. Por defecto Graphite nos retornará un png.

Cambiando el querystring por:
?width=588&height=309&target=stats.gauges.metricas.servers.server*.load&from=00%3A00_20121111&until=23%3A59_20121114&areaMode=stacked
Donde sencillamente le decimos que queremos la carga de todos los servers (stats.gauges.metricas.servers.server*.load) entre el 11 y 14/Nov/2012, el resto de los parámetros son autoexplicativos.

Creo que se comprende la idea con estos dos ejemplos.
Anexo algunas capturas de la interface gráfica WEB de Graphite obtenidas de la web oficial:


En futuros post ahondaremos un poco más en el tema.
Espero les sea de utilidad.
Saludos
Mariano
esta vez es para contarles acerca de una herramienta que me ha impresionado por su simplicidad y potencia, se trata de Graphite, una herramienta opensource escrita en Python con licencia Apache 2.0. Ya en su titulo "Scalable Realtime Graphing" nos invita al menos a hecharle una mirada, aunque con mi poca experiencia, creo que este titulo no termina de definir las cosas buenas de Graphite.
Que hace graphite? para que sirve?, bueno, en otro artículo nos cuentan en simples palabras que Graphite "almacena números que varían con el tiempo y luego permite graficarlos", esto es cierto, pero las características de Graphite son muchas más.
Una de las cosas que más me ha gustado es la simplicidad con la cual tratabajos con Graphite, ahora bien, hay muchas herramientas que nos faciitan este tipo de trabajo, entonces cual es el valor agregado de Graphite, bien, el valor agregado, desde mi punto de vista, es que nos prmitirá almacenar grandes cantidades de datos que serán obtenidos de forma muy eficiente y simple.
Graphite presta servicios para de inyección y obtención de datos, estos servicios no se limitan al uso de un protocolo, en realidad podemos consumir los servicios de diversas formas, entre ellas: http y sockets udp.
Los datos podrán ser obtenidos mediante consultas muy potentes y simples, además estos datos se pueden representar en diversos formatos: png, raw, csv, json y svg
Aquí adjuntaré una serie de características que no son de mi autoria, pertenecen aun colega y amigo cuyo blog es: http://menospeor.tumblr.com
------------------------------------------------------------------------------------------------------------------------------
1) Graphite introduce el concepto de "estadisticas como servicio (EAAS)". Su arquitectura perimte que tengas un servidor con graphite en algún lado y después consumas sus servicios desde distintos puntos. Esto es importante porque libera a las aplicaciones de toda la complejidad relacionada. Al momento de realizar una operación que queremos registrar, normalmente basta UNA SOLA LINEA DE CÓDIGO para enviar el dato y olvidarse del asunto.
2) La característica de realtime es importante también Graphite esta preparado para soportar mucha carga, y cuenta con optimizaciones para poder obtener siempre los datos mas frescos. Por ejemplo, carbon va recibiendo datos y escribe a whisper en bloques, pero cuando le haces una consulta, te abstrae la diferencia entre "datos en cola" y "datos en disco". Esto es notable y es la única herramienta con base de datos round-robin (que conozco!) que lo hace. [Aclaración: hablaremos de carbon, whisper y la arquitectura de Graphite en futuros posts]
3) Comparado con rrdtool (mini post aca), otra diferencia importante es que podes indicar el timestamp de los datos a entrar. Por defecto se asume la hora actual, pero podes cargar datos en el futuro y en el pasado de manera muy sencilla. Esto es fundamental para hacer migraciones y en rrdtool no es para nada trivial obtener la misma funcionalidad. Ademas, y gracias a esta característica te permite enviar datos en lotes para mejorar la performance en red. Podes quedarte juntando datos y mandarlos todos juntos en una sola petición cada 10 minutos, por ejemplo.
4) Soporta Plugins! <-- data-blogger-escaped-aparte.="aparte." data-blogger-escaped-esto="esto" data-blogger-escaped-merece="merece" data-blogger-escaped-post="post" data-blogger-escaped-se="se" data-blogger-escaped-span="span" data-blogger-escaped-un="un">
Gracias Ale!
-------------------------------------------------------------------------------------------------------------------------------
Intentaré mostrar con algunos ejemplos la potencia simpleza y de Graphite:
Ante un requerimiento HTTP/GET de este tipo:
http://graphiteserver/render?target=stats.gauges.metricas.servers.server1.load&from=-10days
Donde stats.gauges.metricas.servers.server1.load es el nombre del indicador y el filtro de consulta es -10days. En otras palabras estoy requiriendo los datos acerca de la carga de mi server1 en los últimos 10 días. Por defecto Graphite nos retornará un png.

Cambiando el querystring por:
?width=588&height=309&target=stats.gauges.metricas.servers.server*.load&from=00%3A00_20121111&until=23%3A59_20121114&areaMode=stacked
Donde sencillamente le decimos que queremos la carga de todos los servers (stats.gauges.metricas.servers.server*.load) entre el 11 y 14/Nov/2012, el resto de los parámetros son autoexplicativos.

Creo que se comprende la idea con estos dos ejemplos.
Anexo algunas capturas de la interface gráfica WEB de Graphite obtenidas de la web oficial:
En futuros post ahondaremos un poco más en el tema.
Espero les sea de utilidad.
Saludos
Mariano
miércoles, noviembre 14, 2012
Pentaho Marketplace
Estimad@s,
este post es para comentarles sobre un plugin de Pentaho que está disponible hace un tiempo, se trata de Pentaho Marcketplace, este plugin, entre otras cosas, permite instalar, desinstalar y actualizar plugins, principalmente CTools y Saiku.
Lo descargan de aquí: http://ci.analytical-labs.com/view/Webdetails/job/Webdetails-Marketplace/
Descarguen la versión tar.gz o zip según su sistema operativo: (marketplace-plugin-TRUNK-SNAPSHOT.tar.gz o marketplace-plugin-TRUNK-SNAPSHOT.zip)
Luego descompriman la carpeta marketplace en ../biserver-ce/pentaho-solutions/system, reinicien el bi-server y estará disponible desde Herramientas/Marketplace o desde un ícono en la barra de herramientas.
Adjunto un screenshot.
 Espero les sea de utilidad.
Espero les sea de utilidad.
Saludos
Mariano
este post es para comentarles sobre un plugin de Pentaho que está disponible hace un tiempo, se trata de Pentaho Marcketplace, este plugin, entre otras cosas, permite instalar, desinstalar y actualizar plugins, principalmente CTools y Saiku.
Lo descargan de aquí: http://ci.analytical-labs.com/view/Webdetails/job/Webdetails-Marketplace/
Descarguen la versión tar.gz o zip según su sistema operativo: (marketplace-plugin-TRUNK-SNAPSHOT.tar.gz o marketplace-plugin-TRUNK-SNAPSHOT.zip)
Luego descompriman la carpeta marketplace en ../biserver-ce/pentaho-solutions/system, reinicien el bi-server y estará disponible desde Herramientas/Marketplace o desde un ícono en la barra de herramientas.
Adjunto un screenshot.

Saludos
Mariano
lunes, octubre 29, 2012
STPivot libre
Estimados,
este post es para darles una excelente noticia, está disponible para descara totalmente gratuita STPivot. Para ello deben acceder a la siguiente URL: http://www.stratebi.com/stpivot, rellenar el formulario correspondiente a la descarga, luego recibirán un mail con la URL usuario/password para la descarga de las versiones de STPivot desde un FTP.
Las versiones disponibles son:

este post es para darles una excelente noticia, está disponible para descara totalmente gratuita STPivot. Para ello deben acceder a la siguiente URL: http://www.stratebi.com/stpivot, rellenar el formulario correspondiente a la descarga, luego recibirán un mail con la URL usuario/password para la descarga de las versiones de STPivot desde un FTP.
Las versiones disponibles son:
- Standalone (corre solo sin necesidad de Pentaho)
- Mondrian (para la versión de despligue web de mondrian)
- Pentaho 3.1 y Pentaho 4.5
Las instrucciones para la instalación estás en los zips y son muy sencillas, sale andando en un par de minutos.
La siguiente es la única prueba que hice por ahora.

Cuando tenga más noticias y realice más pruebas haré los comentarios pertinentes.
Gracias a la gente de StrateBI (nobleza obliga)
Saludos
Mariano
lunes, octubre 08, 2012
Talleres OSBI en la UNdeC
Buenas.
Desde eGluBI queremos agradecer a la Universidad Nacional de Chilecito (UNdeC <ubicación>- La Rioja-Argentina) por invitarnos a disertar en su "V JORNADA DE INFORMATICA Y COMUNICACIONES 2012".
Los temas que tratamos fueron Inteligencia de Negocios, Open Source/Software Libre, Suite Pentaho y Pentaho Data Integration.
Especial agradecimiento a Fernanda Carmona y Horacio Martinez del Pezzo.
Nos hemos sentido muy a gusto y ha sido muy grato pasar unos días por Chilecito.
Saludos
martes, septiembre 04, 2012
Curso OSBI Pentaho 100% a distancia - Octubre 2012
Hola Gente.
Debido a que much@s no han podido incribirse en el curso anterior, desde eGlu BI queríamos invitarl@s a una nueva entrega del curso OSBI Pentaho 100% a distancia. Esta vez será mediante el aula virtual de nuestr@s colegas de Troyanx.

El curso inicia el 1 de Octubre de 2012, los cupos son limitados.
Para más información escribir a: admin@troyanx.com.ar
Link en facebook...
LOS ESPERAMOS!
Saludos
Mariano
Debido a que much@s no han podido incribirse en el curso anterior, desde eGlu BI queríamos invitarl@s a una nueva entrega del curso OSBI Pentaho 100% a distancia. Esta vez será mediante el aula virtual de nuestr@s colegas de Troyanx.

El curso inicia el 1 de Octubre de 2012, los cupos son limitados.
Para más información escribir a: admin@troyanx.com.ar
Link en facebook...
LOS ESPERAMOS!
Saludos
Mariano
lunes, julio 02, 2012
OpenI4Pentaho
Estimados,
estuve probando hace un tiempito OpenI, en su versión Plugin de Pentaho. Es muy simple la instalación, solo copiar la carpeta openi-pentaho-plugin-3.0.1.zip/openi en pentaho-solutions/system y la carpeta openi-pentaho-plugin-3.0.1.zip/openi/openi-sample dentro de pentaho-solutions. Iniciar el bi-server y listo. Una buena opción para reemplazar el viejo pero genial JPivot. Lo descargan de aquí.
Les adjunto una screenshots.



Saludos
Mariano
estuve probando hace un tiempito OpenI, en su versión Plugin de Pentaho. Es muy simple la instalación, solo copiar la carpeta openi-pentaho-plugin-3.0.1.zip/openi en pentaho-solutions/system y la carpeta openi-pentaho-plugin-3.0.1.zip/openi/openi-sample dentro de pentaho-solutions. Iniciar el bi-server y listo. Una buena opción para reemplazar el viejo pero genial JPivot. Lo descargan de aquí.
Les adjunto una screenshots.



Saludos
Mariano
Curso OSBI Pentaho 100% a distancia!

Buenas.
Desde eGlu BI queríamos invitarl@s a una nueva edición del curso OSBI Pentaho, pero esta vez en modalidad 100% a distancia (a través de aula virtual en el IUA).
Los temas que se tratarán serán los siguientes:
Desde eGlu BI queríamos invitarl@s a una nueva edición del curso OSBI Pentaho, pero esta vez en modalidad 100% a distancia (a través de aula virtual en el IUA).
Los temas que se tratarán serán los siguientes:
- Inteligencia de Negocios (Business Intelligence).
- Software Libre, Open Source.
- Data Warehousing.
- Suite Pentaho.
- MySQL, JDBC, JNDI.
- Pentaho Data Integration (PDI).
- BI Server (PAC, PUC).
- Mondrian (PSW).
- JPivot.
- Pentaho Metadata Editor (PME).
- Reportes ad hoc (WAQR).
Antes de concluir el curso se solicitará un trabajo integrador, para la entrega decertificados.
El curso inicia el 23 de Julio de 2012, y posee un cupo máximo de 15 personas.
Quien desee más información con respecto a costos e inscripción puede escribir a: darioSistemas@gmail.com
Saludos
Mariano
martes, mayo 22, 2012
CDC - Community Distributed Cache
CDC, ya está disponible como plugin para Pentaho 4.5
CDC es una más de las excelentes herramientas de WebDetails, una más del abanico CTools.
CDC permite aumentar la performance de componentes Pentaho que utilicen como fuentes de datos a CDA (Community Data Access) y Mondrian. Implementa un cache de memoria distribuida en cluster utilizando el framework Hazelcast.
Más información en el post original de Pedro Alves.
Comienzo las pruebas pertinentes...
Saludos
Mariano
sábado, febrero 11, 2012
martes, enero 17, 2012
STPivot Open Source (Mentira)
Estimad@s,
no estaba seguro si escribir o no este post, pero realmente hay ciertas cosas que me indignan, este es un claro ejemplo:
"STPivot Open Source", los autores de este componente, basado en otro muy conocido JPivot, se están abusando de uno de los términos que nosotros defendemos y a los cuales contribuimos diariamente. La contribución no tiene que ser monetaria (ni obligatoria) necesariamente y si lo es, debe ser eso, una contribución, pero en este caso, si se fijan bien, esta gente se está aprovechando de la comunidad para, lisa y llanamente, vender su producto. No estoy en desacuerdo de que todos los que estamos en este "sector" debemos vivir de algo, de hecho yo cobro por mi trabajo, como la mayoría de ustedes, pero también me paso muchas horas creando contenido, respondiendo a preguntas y creando software open source y libre, sin percibir directamente por ello nada de nada más que, en algunos casos, las gracias. Pero si se obtiene un rédito, no debe ser engañando nadie!. Además, cada vez que descargamos y utilizamos un software open source, realizando los feedbacks emanados de los tests de usuario, estamos contribuyendo de una manera muy fuerte al desarrollo de ese software.
Me gustaría que aporten sus comentarios, no solo aquí, sino también en la web que cito antes.
Personalmente hice varios comentarios allí, como podrán ver, he pedido expresamente que se desambigue la licencia y los términos usados en la web para promocionar el producto. Les pido además que defendamos en lo que creemos y que no solo hagamos uso de lo que tenemos a mano para solucionar un problema o una situación académica o de trabajo, es la única manera que una comunidad de este tipo siga funcionando.
Saludos
Mariano
Suscribirse a:
Entradas (Atom)