Hola Gente,
este post es para recomendarles que le den un vistazo al sitio demo de Cummunity Charts Components versión 2 (CCC 2), es realmente muy bueno y a la ve una galería de lo que se puede hacer con estos componentes que son a cara visible de las CTools.
La página es: http://www.webdetails.pt/ccc2/
Naveguen por la página y prueben todas las opciones de cada gráfico.
Pueden descargar el instalador de CDF con CCC 2 habilitado desde aquí:
http://demo.webdetails.org:8080/pentaho/content/pentaho-cdf-dd/Render?solution=ClearWireless&path=&file=maindashboard.wcdf
Saludos
Mariano
jueves, diciembre 20, 2012
jueves, diciembre 13, 2012
Recursividad en MYSQL con Java
Hola Estimd@s,
he sacado algunas cosas del baúl y las quiero compartir, en este caso se trata de una clase Java que permite ejecutar consultas recursivas en MySQL, la idea surgió a partir de una necesidad en primera instancia y luego me base en la forma en que DB2 la lleva a cabo. Tengo la idea (cuando me haga de algún tiempo) de escribir algún articulo relacionado con recursividad en DB2 ya que es muy útil y por demás interesante. Por ahora solo esto.
Pueden descargar la clases desde aquí:
Copio el readme.txt que escribí para poder usar esta clase.
he sacado algunas cosas del baúl y las quiero compartir, en este caso se trata de una clase Java que permite ejecutar consultas recursivas en MySQL, la idea surgió a partir de una necesidad en primera instancia y luego me base en la forma en que DB2 la lleva a cabo. Tengo la idea (cuando me haga de algún tiempo) de escribir algún articulo relacionado con recursividad en DB2 ya que es muy útil y por demás interesante. Por ahora solo esto.
Pueden descargar la clases desde aquí:
Copio el readme.txt que escribí para poder usar esta clase.
Esta clase está basada en la idea de recursividad de DB2.
La clase ar.com.magm.jdbc.SQLRecursivo permite implementar recursividad en MySQL.
Aún no está bien testeada la indexación que es fundamental cuando se trabaja con muchos datos
La tabla con la que funciona la demo (clase Test) es:
CREATE TABLE `practico`.`arbol` (
`idPadre` integer NOT NULL,
`idHijo` integer NOT NULL,
`cantidad` integer NOT NULL,
PRIMARY KEY (`idPadre`, `idHijo`)
)
Agunos datos:
INSERT INTO `practico`.`arbol` VALUES
(3,8,1),
(5,6,3),
(2,5,2),
(1,4,2),
(1,3,2),
(1,2,1);
Forma el siguiente árbol:
1
+--2
| +--5
| +--6
|
+--3
| +--8
|
+--4
El uso es muy simple, solo hay que crear una instancia de la clase SQLRecursivo, el constructor pide
una conexión JDBC, ejemplo;
SQLRecursivo sqlRec = new SQLRecursivo(cn);
Luego llamar al método recursivo(consultaInicial, aliasTablaPadre, consultaRecursiva, indexKey)
Este método retornará el resultado en forma de ResultSet.
Los parámetros son:
@param consultaInicial
consulta que produce la población inicial de datos.
@param aliasTablaPadre
alias que se utilizará en la consulta recursiva para la tabla padre
@param consultaRecursiva
consulta que obtiene el resto de los datos en forma recursiva.
Esta consulta contiene la lógica de corte de cotrol.
Se hace referencia a la tabla padre con: //TablaPadre//
@param indexKey
representa la clave del índice/indices que se crearán sobre la
tabla padre, la forma es:
(opciones indice1)\t(clave indice1)\n(opciones indice2)\t(clave indice2),
en otras palabras el \n determina la cantidad de índices a crear,
el \t separa las opciones de la clave.
Para no crear ningún índice enviar "" o null.
Ejemplo:
UNIQUE CLUSTERED\tidHijo,idFiltroArbol,idFiltroGeneral\nNONCLUSTERED\tcc
Se crearán:
CREATE UNIQUE CLUSTERED INDEX IX0_##TablaPadre ON ##TablaPadre (idHijo,idFiltroArbol,idFiltroGeneral)
y
CREATE NONCLUSTERED INDEX IX1_TablaPadre ON ##TablaPadre (cc)
Se recomienda probar en el test las siguientes consultas:
String consultaInicial = "SELECT idPadre,idHijo FROM arbol where idPadre=1"; //Obtiene el árbol completo
para obtener el árbol completo o:
String consultaInicial = "SELECT idPadre,idHijo FROM arbol where idPadre=2"; //Obtiene el subarbol del nodo 2
En la consulta recursiva se puede (y en general se debe) hacer referencia a la tabla padre (consulta inicial),
esto se hace con la expresión: //TablaPadre//, esto se puede ver en el ejemplo. La tabla tiene un alias,
que este ejemplo es 'padre' y es el segundo argumento del método recursivo. Por ello en la consulta se ve:
... a.idPadre=padre.idHijo
String consultaRecursiva = "SELECT a.idPadre,a.idHijo FROM arbol a,//TablaPadre// WHERE a.idPadre=padre.idHijo";
Enjoy
Mariano
miércoles, diciembre 12, 2012
Valores de filas afectadas y claves identidad en DB2
Estimad@s,
expongo aquí algunas formas de trabajar con los datos recién insertados en tablas DB2.
Muchas veces es necesario conocer el último id insertado en una columna identity (auto-numérica) o también la última o últimas filas insertadas en una tabla.
Muchos desarrolladores tratan esto con algunas prácticas que no son muy buenas, algunos ejemplos pueden ser ejecutar una consulta del estilo SELECT MAX(id) FROM tabla luego de insertar, SELECT * FROM tabla WHERE descripcion='algún dato unique que se tenía antes de insertar' o almacenar últimos valores de clave en una tabla, esta última la peor de las prácticas.
Existen otros casos, pero casi todos tienen en común que no dan soporte a la concurrencia y que en general son muy ineficientes.
DB2 posee una serie de características que permiten lidiar con estos problemas y darles una solución sencilla y elegante, además se tendrá en cuenta la concurrencia y la eficiencia en la ejecución.
Secuencias:
Una manera puede ser utilizar secuencias. Las secuencias son objetos de la base de datos que permiten generar números en secuencia (valga aquí la redundancia) a pedido, además permite obtener el último número generado en la secuencia. Veamos un pequeño ejemplo de como crear y utilizar una secuencia.
Creamos la tabla que utilizaremos como ejemplo:
CREATE TABLE EJ_SECUENCIA (
id BIGINT NOT NULL,
descripcion VARCHAR(50) NOT NULL,
CONSTRAINT PK_EJEMPLO PRIMARY KEY (id)
);
Luego la secuencia seq1 que inicia en 1 e incrementa de 1.
CREATE SEQUENCE seq1 AS INTEGER START WITH 1 INCREMENT BY 1
La salida será:
1
-----------
1
1 registro(s) seleccionado(s).
Si ejecutamos ahora:
INSERT INTO EJ_SECUENCIA (id, descripcion) VALUES
(NEXTVAL FOR seq1, 'b'),
(NEXTVAL FOR seq1, 'c'),
(NEXTVAL FOR seq1, 'd');
Obtendremos:
SELECT * FROM DB2ADMIN.EJ_SECUENCIA
ID DESCRIPCION
-------------------- -------------
1 a
2 b
3 c
4 d
4 registro(s) seleccionado(s).
Como se puede apreciar el uso de las secuencia es muy sencillo y flexible.
Autoincrementales y filas afectadas:
Creamos la tabla de ejemplo:
CREATE TABLE EJ_IDS (
id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY,
descripcion VARCHAR(10) NOT NULL,
CONSTRAINT PK_IDS PRIMARY KEY (id)
);
Insertamos algunos valores:
SELECT * FROM EJ_IDS
Obtendremos:
ID DESCRIPCION
-------------------- ---------------
1 a
2 b
3 c
3 registro(s) seleccionado(s).
Luego ejecutando :
SELECT * FROM FINAL TABLE (INSERT INTO EJ_IDS (descripcion) VALUES ('e'),('f'),('g'))
La sentencia anterior cumplirá dos funciones, por un lado se insertarán tres nuevas filas y por otro se obtendrán de la consulta a la tabla 'FINAL TABLE'
ID DESCRIPCION
-------------------- -----------
4 e
5 f
6 g
3 registro(s) seleccionado(s).
También podemos utilizar 'FINAL TABLE' en modificaciones:
SELECT * FROM FINAL TABLE (UPDATE EJ_IDS SET descripcion = descripcion || '-nuevo' WHERE MOD(ID,2)=0)
Obtendremos:
ID DESCRIPCION
-------------------- -----------
2 b-nuevo
4 e-nuevo
6 g-nuevo
3 registro(s) seleccionado(s).
Además de 'FINAL TABLE' podemos utilizar 'NEW TABLE' la diferencia es que con 'NEW TABLE' obtendremos los valores de la tabla antes que se ejecuten las restricciones referenciales (claves foráneas) los triggers definidos como after:
Para obtener las filas borradas:
SELECT * FROM OLD TABLE (DELETE FROM EJ_IDS WHERE MOD(ID,3)=0)
ID DESCRIPCION
-------------------- -----------
3 c
6 c-nuevo
2 registro(s) seleccionado(s).
Espero que les sea útil.
Saludos
Mariano
expongo aquí algunas formas de trabajar con los datos recién insertados en tablas DB2.
Muchas veces es necesario conocer el último id insertado en una columna identity (auto-numérica) o también la última o últimas filas insertadas en una tabla.
Muchos desarrolladores tratan esto con algunas prácticas que no son muy buenas, algunos ejemplos pueden ser ejecutar una consulta del estilo SELECT MAX(id) FROM tabla luego de insertar, SELECT * FROM tabla WHERE descripcion='algún dato unique que se tenía antes de insertar' o almacenar últimos valores de clave en una tabla, esta última la peor de las prácticas.
Existen otros casos, pero casi todos tienen en común que no dan soporte a la concurrencia y que en general son muy ineficientes.
DB2 posee una serie de características que permiten lidiar con estos problemas y darles una solución sencilla y elegante, además se tendrá en cuenta la concurrencia y la eficiencia en la ejecución.
Secuencias:
Una manera puede ser utilizar secuencias. Las secuencias son objetos de la base de datos que permiten generar números en secuencia (valga aquí la redundancia) a pedido, además permite obtener el último número generado en la secuencia. Veamos un pequeño ejemplo de como crear y utilizar una secuencia.
Creamos la tabla que utilizaremos como ejemplo:
CREATE TABLE EJ_SECUENCIA (
id BIGINT NOT NULL,
descripcion VARCHAR(50) NOT NULL,
CONSTRAINT PK_EJEMPLO PRIMARY KEY (id)
);
Luego la secuencia seq1 que inicia en 1 e incrementa de 1.
CREATE SEQUENCE seq1 AS INTEGER START WITH 1 INCREMENT BY 1
La sintaxis de las secuencias en DB2 es muy amplia y permite definir muchas opciones como: ciclos, secuencias decrementales, etc.
Las secuencias tienen dos métodos asociados, PREVVAL que permite obtener el último número generado (no puede utilizarse luego de crear la secuencia, debe generarse al menos un valor antes de ejecutar este método) y NEXTVAL que permite generar un nuevo valor de la secuencia. Veamos con un ejemplo como insertar valores en la tabla EJ_SECUENCIA con esta secuencia.
INSERT INTO EJ_SECUENCIA (id, descripcion) VALUES (NEXTVAL FOR seq1, 'a');
VALUES (PREVVAL FOR seq1);
La salida será:
1
-----------
1
1 registro(s) seleccionado(s).
Si ejecutamos ahora:
INSERT INTO EJ_SECUENCIA (id, descripcion) VALUES
(NEXTVAL FOR seq1, 'b'),
(NEXTVAL FOR seq1, 'c'),
(NEXTVAL FOR seq1, 'd');
Obtendremos:
SELECT * FROM DB2ADMIN.EJ_SECUENCIA
ID DESCRIPCION
-------------------- -------------
1 a
2 b
3 c
4 d
4 registro(s) seleccionado(s).
Como se puede apreciar el uso de las secuencia es muy sencillo y flexible.
Autoincrementales y filas afectadas:
Creamos la tabla de ejemplo:
CREATE TABLE EJ_IDS (
id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY,
descripcion VARCHAR(10) NOT NULL,
CONSTRAINT PK_IDS PRIMARY KEY (id)
);
Insertamos algunos valores:
INSERT INTO EJ_IDS (descripcion) VALUES ('a'),('b'),('c');
Noten que solo es necesario dar valores a la columna descripcion, DB2 se encargará dar valores a la columna id.
Luego de consultar la tabla:
Obtendremos:
ID DESCRIPCION
-------------------- ---------------
1 a
2 b
3 c
3 registro(s) seleccionado(s).
Luego ejecutando :
VALUES (IDENTITY_VAL_LOCAL())
La salida será:
1
-----------
3
1 registro(s) seleccionado(s).
Para finalizar una herramienta excelente para obtener las filas afectadas, denominamos filas afectadas a las filas insertadas o que cumplen un predicado y por ello son modificadas o eliminadas.
SELECT * FROM FINAL TABLE (INSERT INTO EJ_IDS (descripcion) VALUES ('e'),('f'),('g'))
La sentencia anterior cumplirá dos funciones, por un lado se insertarán tres nuevas filas y por otro se obtendrán de la consulta a la tabla 'FINAL TABLE'
ID DESCRIPCION
-------------------- -----------
4 e
5 f
6 g
3 registro(s) seleccionado(s).
También podemos utilizar 'FINAL TABLE' en modificaciones:
SELECT * FROM FINAL TABLE (UPDATE EJ_IDS SET descripcion = descripcion || '-nuevo' WHERE MOD(ID,2)=0)
Obtendremos:
ID DESCRIPCION
-------------------- -----------
2 b-nuevo
4 e-nuevo
6 g-nuevo
3 registro(s) seleccionado(s).
Además de 'FINAL TABLE' podemos utilizar 'NEW TABLE' la diferencia es que con 'NEW TABLE' obtendremos los valores de la tabla antes que se ejecuten las restricciones referenciales (claves foráneas) los triggers definidos como after:
Para obtener las filas borradas:
SELECT * FROM OLD TABLE (DELETE FROM EJ_IDS WHERE MOD(ID,3)=0)
ID DESCRIPCION
-------------------- -----------
3 c
6 c-nuevo
2 registro(s) seleccionado(s).
Espero que les sea útil.
Saludos
Mariano
miércoles, diciembre 05, 2012
Expandir Colapsar con Pentaho Reporting salida HTML
Estimad@s,
esta vez escribo para compartir con ustedes algunos experimentos con Pentaho Reporting (PRD).
El caso es que viendo los ejemplos avanzados de PRD y tratando de mejorarlos en algunos casos, salen cosas como lo que les voy a contar en este post. Se trata de un método para expandir y colapsar cabeceras de grupo y detalles de forma muy sencilla.
Este ejemplo tiene como idea inicial, la propuesta por el ejemplo "HTML Actions.prpt", ejemplo que pueden encontrar si seleccionan del menú principal:
Help / Sample Reports / Advanced / HTML Actions
En el editor se ve así:

Ejecutándose en vista HTML así:

La verdad, muy bueno!, les recomiendo que lo vean.
Es la posibilidad de ocultar partes de la jerarquía lo que me llamó la atención y en lo que me puse a experimentar. De los experimentos salió una pequeña serie de funciones javascript genéricas que permiten trabajar con hasta 9 niveles jerárquicos siguiendo dos simples pasos por cabecera de grupo. En este post explicaré en detalle como hacerlo. Ahora veamos el resultado final:

Los datos que contiene la tabla forman una jerarquía que puede verse en la imagen anterior y que reproduzco a continuación:
Zona
Año
( Cliente | Importe )
Una Zona tiene varios Años y en un Año por Zona pueden existir varios hechos, cada hecho es un importe de venta a un cliente determinado. La cardinalidad es uno a muchos de zona hacia año y de uno a muchos de zona/año hacia los hechos. Los datos están ordenados con el criterio de agrupamiento, esto es: Zona+Año, se puede agregar el cliente y/o el importe, aunque esto último es anecdótico.
La siguiente es una captura de la tabla:

Luego tenemos las librerías javascript requeridas, a estas librerías y/o reglas de estilo CSS, las agregamos en el header del documento principal, a esto lo hacemos editando el atributo append-header de Master Report. Lo anterior se traduce en algo tan sencillo como que se agregará ese snippet al header del documento HTML cuando el reporte se exporte a ese formato.
Respecto a JQuery, solo descarguen la versión mínima, la abren con un editor de textos, seleccionan todo, copian y lo pegan en esta sección (debe ser lo primero) rodeado de tags < script >
A continuación una captura de como acceder a esta característica en el reporte:

Impresionante las posibilidades que brinda PRD no?
No entraré en detalle de las funciones que he creado, si algun@ está interesad@, solo debe hacer el comentario pertinente. Sin duda que valoraré cualquier aporte o mejora al código.
Teniendo en claro esto, manos a la obra, ahora la parte más sencilla, desarrollar el reporte.








Bueno, hasta aquí nada nuevo bajo el sol, verdad?
Es una de las cosas que más me gusta de esto, la simpleza.
Lo que sigue es lo que le da dinamismo al reporte y permite u otorga la posibilidad de expandir/colapsar datos.
Implementación de la funcionanlidad de expandir/colapsar:
Solo tres atributos hay que configurar por grupo, dos de los cuales implementan la funcionalidad, el tercero es solo adorno visual.
El primer atributo que configuraremos será xml-id, este atributo se transforma luego en un atributo id para el elemento HTML que renderiza el elemento Message, particularmente se trata de un elemento td.
Veamos en una imagen como hacerlo y que valor colocar para el grupo año.

El valor del atributo xml-id para este caso es =CONCATENATE("j2_";[zona];"_";[año]), esta expresión data como resultado para la zona Este y el año 2012 "j2_Este_2012", esto generará un valor único para cada grupo, muy importante comprender el concepto.
La primera parte de la cadena "j2_" es parte de la implementación, 2 significa que el grupo está 2do en la jerarquía, en este caso el 1ero será el grupo zona.
El render HTML generará algo así:
< td id="j2_Este_2010" colspan="3" > - Año: 2012 < / td >
Si se comprendió lo anterior, se puede deducir el valor para el atributo xml-id de zona: =CONCATENATE("j1_";[zona])
Bien, si hasta aquí se comprendió, ya está, lo que resta es mecánico y muy simple.
Vamos a establecer el valor al atributo on-click de los elementos Message que representan los grupos.

En este caso, en la figura anterior, se muestra como establecer el valor para el grupo zona. El valor asignado es: ="expandCollapse(this, true)", esto es siempre igual, solo vale la pena aclarar que el segundo parámetro (valor true) implica que los valores de los grupos contienen como primer caracter un "+", esto será cambiado automáticamente por un "-" al expandir y vuelta al "+" al colapsar (and so on...).
Recuerden asignar el mismo valor al grupo año.
[Nota mental: estaría muy bueno poder enviar como parámetro el nombre de las clases CSS que deben ser asignadas al grupo cuando está colapsado y cuando está expandido. ¿Alguien se anima a aportar esta característica?]
El reporte ya posee la característica de expandir/colapsar en render HTML. Solo resta mejorar la apariencia en la interacción, hablo de que cuando el usuario pase el mouse por encima del grupo vea un cursor más acorde a lo que el grupo permite hacer. Lo haremos usando una clase CSS que ya está entre los snippets de los que hablamos al inicio. La clase se llama mouse y el código CSS es el siguiente:
.mouse {
cursor: pointer;
}
Bien, ahora solo debemos establecer la clase mouse a los elementos Message que representan los grupos del reporte. Veamos esto en una figura para el grupo año:

Repetir esto con el grupo zona y listo!
Para probarlo solo debemos seleccionar la vista previa en HTML:
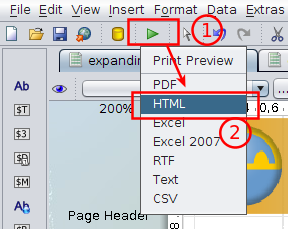
esta vez escribo para compartir con ustedes algunos experimentos con Pentaho Reporting (PRD).
El caso es que viendo los ejemplos avanzados de PRD y tratando de mejorarlos en algunos casos, salen cosas como lo que les voy a contar en este post. Se trata de un método para expandir y colapsar cabeceras de grupo y detalles de forma muy sencilla.
Este ejemplo tiene como idea inicial, la propuesta por el ejemplo "HTML Actions.prpt", ejemplo que pueden encontrar si seleccionan del menú principal:
Help / Sample Reports / Advanced / HTML Actions
En el editor se ve así:
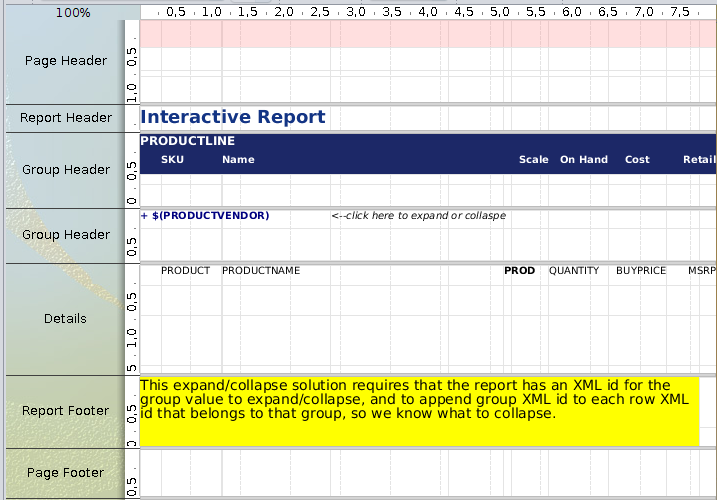
Ejecutándose en vista HTML así:

La verdad, muy bueno!, les recomiendo que lo vean.
Es la posibilidad de ocultar partes de la jerarquía lo que me llamó la atención y en lo que me puse a experimentar. De los experimentos salió una pequeña serie de funciones javascript genéricas que permiten trabajar con hasta 9 niveles jerárquicos siguiendo dos simples pasos por cabecera de grupo. En este post explicaré en detalle como hacerlo. Ahora veamos el resultado final:
Bien, aquellos que tengan un poco de curiosidad sigan adelante, el resto puede obviar de aquí en adelante.
Partimos de un reporte inicial que tiene muy poco, solo la fuente de datos (se trata de una tabla estática embebida en el reporte) y las librerías javascript necesarias ya embebidas, explicaré en que lugar y como hacerlo. Al reporte inicial lo pueden descargar desde aquí.
Para este caso he utilizado la versión experimental de PRD 4, la pueden descargar desde aquí, aunque se puede hacer sin problema con versiones anteriores (no se con exactitud a partir de cual).
Así se ve el reporte inicial en PRD:

Como pueden ver he ocultado todas las bandas que no son necesarias en el reporte.
Zona
Año
( Cliente | Importe )
Una Zona tiene varios Años y en un Año por Zona pueden existir varios hechos, cada hecho es un importe de venta a un cliente determinado. La cardinalidad es uno a muchos de zona hacia año y de uno a muchos de zona/año hacia los hechos. Los datos están ordenados con el criterio de agrupamiento, esto es: Zona+Año, se puede agregar el cliente y/o el importe, aunque esto último es anecdótico.
La siguiente es una captura de la tabla:

Luego tenemos las librerías javascript requeridas, a estas librerías y/o reglas de estilo CSS, las agregamos en el header del documento principal, a esto lo hacemos editando el atributo append-header de Master Report. Lo anterior se traduce en algo tan sencillo como que se agregará ese snippet al header del documento HTML cuando el reporte se exporte a ese formato.
Respecto a JQuery, solo descarguen la versión mínima, la abren con un editor de textos, seleccionan todo, copian y lo pegan en esta sección (debe ser lo primero) rodeado de tags < script >
A continuación una captura de como acceder a esta característica en el reporte:

Impresionante las posibilidades que brinda PRD no?
No entraré en detalle de las funciones que he creado, si algun@ está interesad@, solo debe hacer el comentario pertinente. Sin duda que valoraré cualquier aporte o mejora al código.
Teniendo en claro esto, manos a la obra, ahora la parte más sencilla, desarrollar el reporte.

Luego completar los datos del grupo.

Debemos definir ahora el grupo principal, para hacerlo debemos:

Luego completamos los datos:

Hasta aquí, la estructura del reporte debería quedar así:

Ahora coloquemos los elementos en el reporte.
El Detalle:
Primero un rectángulo, le damos el color (pueden usar el selector de combinación de color que está en la barra de herramientas) y las dimensiones. Luego arrastramos el campo cliente y el campo importe al detalle dentro del rectángulo. Será necesario darle una combinación de colores a los campos también. Pueden ver los detalles en la siguiente figura:

Los Grupos:
Como en el caso anterior, primero arrastramos un rectángulo en cada uno de las cabeceras de grupo. La cabecera de grupo que se encuentra en la parte superior pertenece al grupo de mayor jerarquía, en este caso se trata de zona. Luego de colocarlos en su lugar, habrá que asignar un color a cada rectángulo.

Procedemos ahora a colocar sobre los rectángulos los elementos que aportarán los datos, arrastraremos dos elementos Message, uno sobre cada rectángulo, le asignamos la combinación de color y establecemos el atributo value para cada uno.

Valores de value para:
zona: - Zona $(zona)
año: - Año $(año)
Bueno, hasta aquí nada nuevo bajo el sol, verdad?
Es una de las cosas que más me gusta de esto, la simpleza.
Lo que sigue es lo que le da dinamismo al reporte y permite u otorga la posibilidad de expandir/colapsar datos.
Implementación de la funcionanlidad de expandir/colapsar:
Solo tres atributos hay que configurar por grupo, dos de los cuales implementan la funcionalidad, el tercero es solo adorno visual.
El primer atributo que configuraremos será xml-id, este atributo se transforma luego en un atributo id para el elemento HTML que renderiza el elemento Message, particularmente se trata de un elemento td.
Veamos en una imagen como hacerlo y que valor colocar para el grupo año.

El valor del atributo xml-id para este caso es =CONCATENATE("j2_";[zona];"_";[año]), esta expresión data como resultado para la zona Este y el año 2012 "j2_Este_2012", esto generará un valor único para cada grupo, muy importante comprender el concepto.
La primera parte de la cadena "j2_" es parte de la implementación, 2 significa que el grupo está 2do en la jerarquía, en este caso el 1ero será el grupo zona.
El render HTML generará algo así:
< td id="j2_Este_2010" colspan="3" > - Año: 2012 < / td >
Si se comprendió lo anterior, se puede deducir el valor para el atributo xml-id de zona: =CONCATENATE("j1_";[zona])
Bien, si hasta aquí se comprendió, ya está, lo que resta es mecánico y muy simple.
Vamos a establecer el valor al atributo on-click de los elementos Message que representan los grupos.

En este caso, en la figura anterior, se muestra como establecer el valor para el grupo zona. El valor asignado es: ="expandCollapse(this, true)", esto es siempre igual, solo vale la pena aclarar que el segundo parámetro (valor true) implica que los valores de los grupos contienen como primer caracter un "+", esto será cambiado automáticamente por un "-" al expandir y vuelta al "+" al colapsar (and so on...).
Recuerden asignar el mismo valor al grupo año.
[Nota mental: estaría muy bueno poder enviar como parámetro el nombre de las clases CSS que deben ser asignadas al grupo cuando está colapsado y cuando está expandido. ¿Alguien se anima a aportar esta característica?]
El reporte ya posee la característica de expandir/colapsar en render HTML. Solo resta mejorar la apariencia en la interacción, hablo de que cuando el usuario pase el mouse por encima del grupo vea un cursor más acorde a lo que el grupo permite hacer. Lo haremos usando una clase CSS que ya está entre los snippets de los que hablamos al inicio. La clase se llama mouse y el código CSS es el siguiente:
.mouse {
cursor: pointer;
}
Bien, ahora solo debemos establecer la clase mouse a los elementos Message que representan los grupos del reporte. Veamos esto en una figura para el grupo año:

Repetir esto con el grupo zona y listo!
Para probarlo solo debemos seleccionar la vista previa en HTML:
Bien, hemos finalizado, espero que les sea de utilidad.
Pueden descargar la versión final desde aquí.
Saludos
Mariano
Suscribirse a:
Entradas (Atom)